
728x90
인덱스 (Index)
인덱스는 조회만을 위한 오브젝트로, 기본적인 목적은 검색 성능의 최적화이다. 하지만 INSERT, UPDATE, DELETE 등과 같은 DML 작업은 인덱스를 함께 변경해야 하기 때문에 오히려 성능이 느려질 수 있다.
트리 기반 인덱스
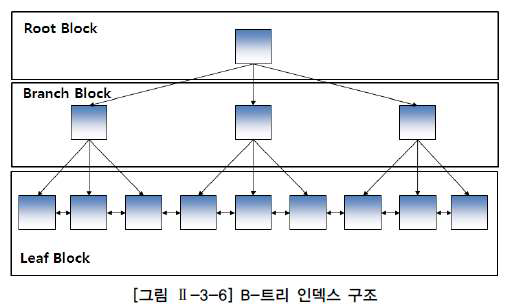
DBMS에서 가장 일반적인 인덱스는 B-트리(Blance Tree) 인덱스이다.
B-트리 인덱스는 브랜치 블록(Branch Block)과 리프 블록(Leaf Block)으로 구성되며, 브랜치 블록 중 가장 상위에 있는 블록을 루트 블록 (Root Block)이라고 한다.
브랜치 블록은 분기를 목적으로 하고 리프블록은 인덱스를 구성하는 컬럼의 값으로 정렬된다.
일반적으로 OLTP(Online Transaction Processing) 시스템 환경에서 가장 많이 사용된다.
CLUSTERED 인덱스
CLUSTERED 인덱스는 인덱스의 리프 페이지가 곧 데이터 페이지며, 리프 페이지의 모든 데이터는 인덱스 키 컬럼 순으로 물리적 정렬이 되어 저장된다.
BITMAP 인덱스
BITMAP 인덱스는 시스템에서 사용될 질의를 시스템 구현 시 모두 알 수 없는 경우인 AD-HOC 질의 환경을 위해서 설계 되었으며, 하나의 인덱스 키 엔트리가 많은 행에 대한 포인터를 저장하고 있는 구조이다.
테이블 스캔
전체 테이블 스캔 (FTS, Full Table Scan)
인덱스 스캔
인덱스 유일 스캔
- 유일 인덱스(Unique Index)를 사용하여 단 하나의 데이터를 추출하는 방식이다.
- 유일 인덱스는 중복을 허락하지 않는 인덱스이다.
- 유일 인덱스 구성 컬럼에 모두 '='로 값이 주어지면 결과는 최대 1건이 된다.
- 인덱스 유일 스캔은 유일 인덱스 구성 컬럼에 대해 모두 '='로 값이 주어진 경우에만 가능한 인덱스 스캔 방식이다.
인덱스 범위 스캔
- 인덱스를 이용하여 데이터를 추출하는 방식이다.
- 결과 건수 만큼 반환하지만 결과가 없으면 한 건도 반환하지 않을 수 있다.
728x90
'자격증 > SQLD' 카테고리의 다른 글
| [SQLD] DROP vs TRUNCATE vs DELETE (0) | 2023.09.04 |
|---|---|
| [SQLD] SQL 최적화 기본 원리 - 조인 수행 원리 (0) | 2023.09.01 |
| [SQLD] SQL 최적화 기본 원리 - 옵티마이저와 실행계획 (0) | 2023.08.31 |
| [SQLD] SQL 활용 - 절차형 SQL (0) | 2023.08.31 |
| [SQLD] SQL 활용 - DCL(Data Control Language) (0) | 2023.08.31 |